728x90
반응형
웹크롤링 진도가 잘 나가고 있습니다. 이전에는 특정페이지에서 text만 가져오는 코딩을 했었습니다.
다시 한번 복습해 보겠습니다. 코딩을 하루 이틀 안 하다 보면, 또 잊어 버리니까요. 에빙하우스 망각곡선 아시죠?
먼저 네이버에서 테슬라 뉴스 기사를 그냥 가져오는 코딩을 써 보면 어떻게 될까요?
요걸 가져 오고 싶습니다.

사이트 주소는 여기입니다.
https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%ED%85%8C%EC%8A%AC%EB%9D%BC
테슬라 : 네이버 뉴스검색
'테슬라'의 네이버 뉴스검색 결과입니다.
search.naver.com
이걸 이렇게 코딩합니다.
import requests
from bs4 import BeautifulSoup
x = requests.get("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%ED%85%8C%EC%8A%AC%EB%9D%BC")
y = x.text
z = BeautifulSoup(y, "html.parser")
print(z)
그러면 결과값이 이렇게 나옵니다.
웹페이지에서 F12를 눌렀을 때 보이는 모든 코딩들이 다 보입니다. 아니함만 못하죠?
자, 그래서 이렇게 튜닝을 해야 합니다. 그래서 여기서 "헤드라인(제목)"만 가져오고 싶으시다면 어떻게 코딩을 해야 할까요?
import requests
from bs4 import BeautifulSoup
x = requests.get("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%ED%85%8C%EC%8A%AC%EB%9D%BC")
y = x.text
z = BeautifulSoup(y, "html.parser")
print(z.title)
print(z) 대신 print(z.title)만 변주를 줬습니다. 결과는요?
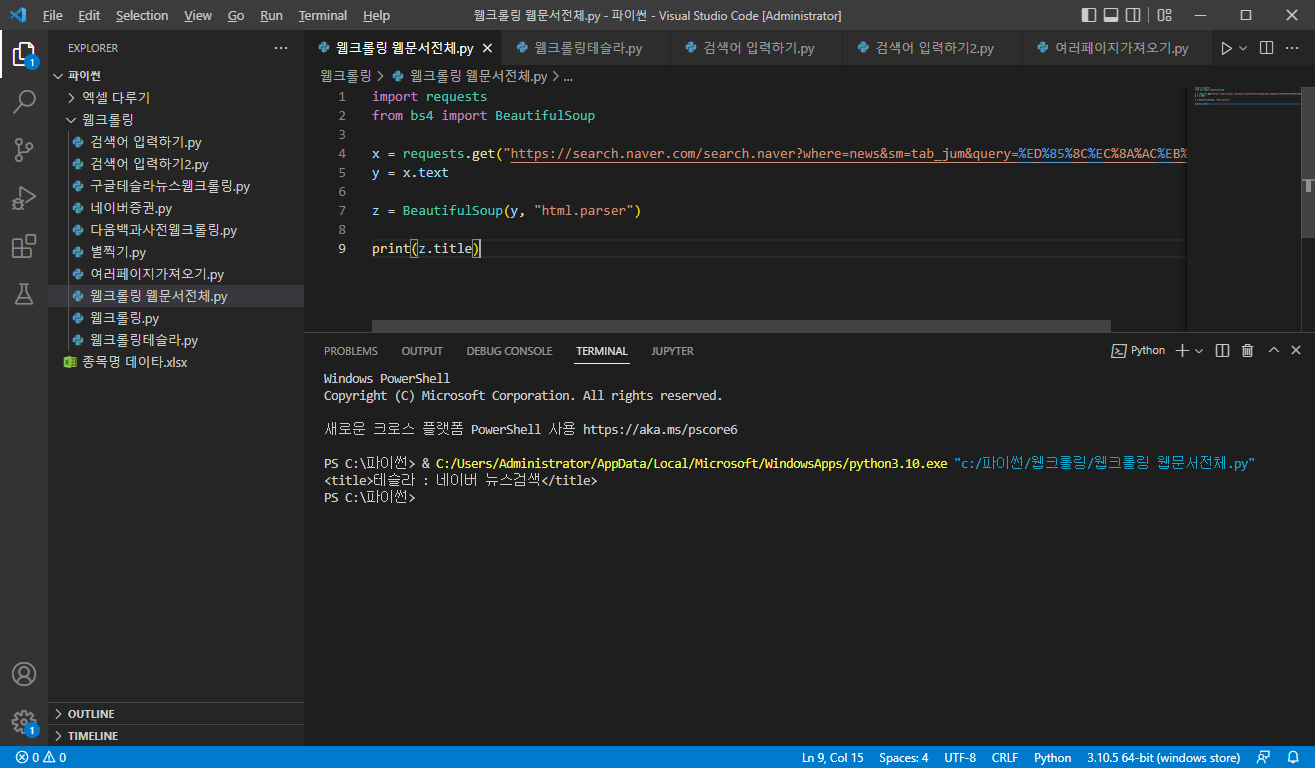
정말 타이틀만 나왔습니다.
이상한 것들을 다 걷어내고 텍스트만 남기는 작업을 다음 시간에 해 보겠습니다.
감사합니다.
728x90
반응형
'파이썬 배우기' 카테고리의 다른 글
| 파이썬으로 웹크롤링 해 보기!!! 번외편 #3편 (교보문고 베스트셀러 웹크롤링!!!) (0) | 2022.07.31 |
|---|---|
| 파이썬으로 웹크롤링 해 보기!!! 번외편 #2편 (진도 나가기 전 복습하기!!!) (0) | 2022.07.26 |
| 파이썬으로 웹크롤링 해 보기!!! 6편 (ft. 검색어 변경하기 - 이어서) (0) | 2022.07.05 |
| 파이썬으로 웹크롤링 해 보기!!! 5편 (ft. 검색어 변경하기) (0) | 2022.07.05 |
| 파이썬으로 엑셀 다루기 1편 (0) | 2022.06.28 |




댓글