자, 저번 시간에 여기까지 나갔습니다.
파이썬으로 웹크롤링 해 보기!!! 번외편 #2편 (진도 나가기 전 복습하기!!!)
바로 저번 시간에 이어서 나가보겠습니다. 파이썬으로 웹크롤링 해 보기!!! 번외편 (진도 나가기 전 복습하기!!!) 웹크롤링 진도가 잘 나가고 있습니다. 이전에는 특정페이지에서 text만 가져오는
booknomad.tistory.com
저번 시간에 덕지덕지 붙어 있는 걸 날려버리기로 했었죠?^^
단순히 생각하면 텍스트만 남긴다, 라는 말이 생각나죠? 이걸 어떻게 코딩으로 할까요?
헤드라인 기사를 출력하는 함수를 텍스트만 남기는 걸 반복한다.
for문 기억나시나요?
for문의 기본 공식은 뭐라고 했죠?
for i in range( ):
어떤 범위(range) 안에서 i를 반복해라! 반드시 맨 뒤에는 ":"로 마감하셔야 합니다!!!
import requests
여기에서, i가 코딩을 포함한 헤드라인 전체의 범위입니다. 즉 모집단입니다. 그 in 뒤의 range()가 바로 i라는 겁니다.
그러니까 새로운 변수 zz를 i라는 모집단(범위)에 계속 집어넣으면서 반복하는데, 반복할 때마다 뭘해주면 되죠?
코딩 말고 오로지 text 만 출력해라
for zz in 모집단:

제가 이해를 돕기 위해 심지어 변수를
ㅋㅋ
으로 집어 넣었습니다.
for ㅋㅋ in 모집단:
최종 코딩입니다.
그대로 복붙하셔서, 사이트 주소와 select 안 부분, 그러니까 어떤 정보를 가져올지만 정하면 어떤 사이트에서도 정보를 추가로 가져올 수 있습니다. 실제로 생각나는 사이트 들어가 보겠습니다. 제가 책 좋아하니까 교보문고 들어가 보겠습니다.
http://www.kyobobook.co.kr/bestSellerNew/bestseller.laf?orderClick=d79
교보문고 종합 주간 집계 | 국내도서 | 베스트셀러 - 교보문고
www.kyobobook.co.kr
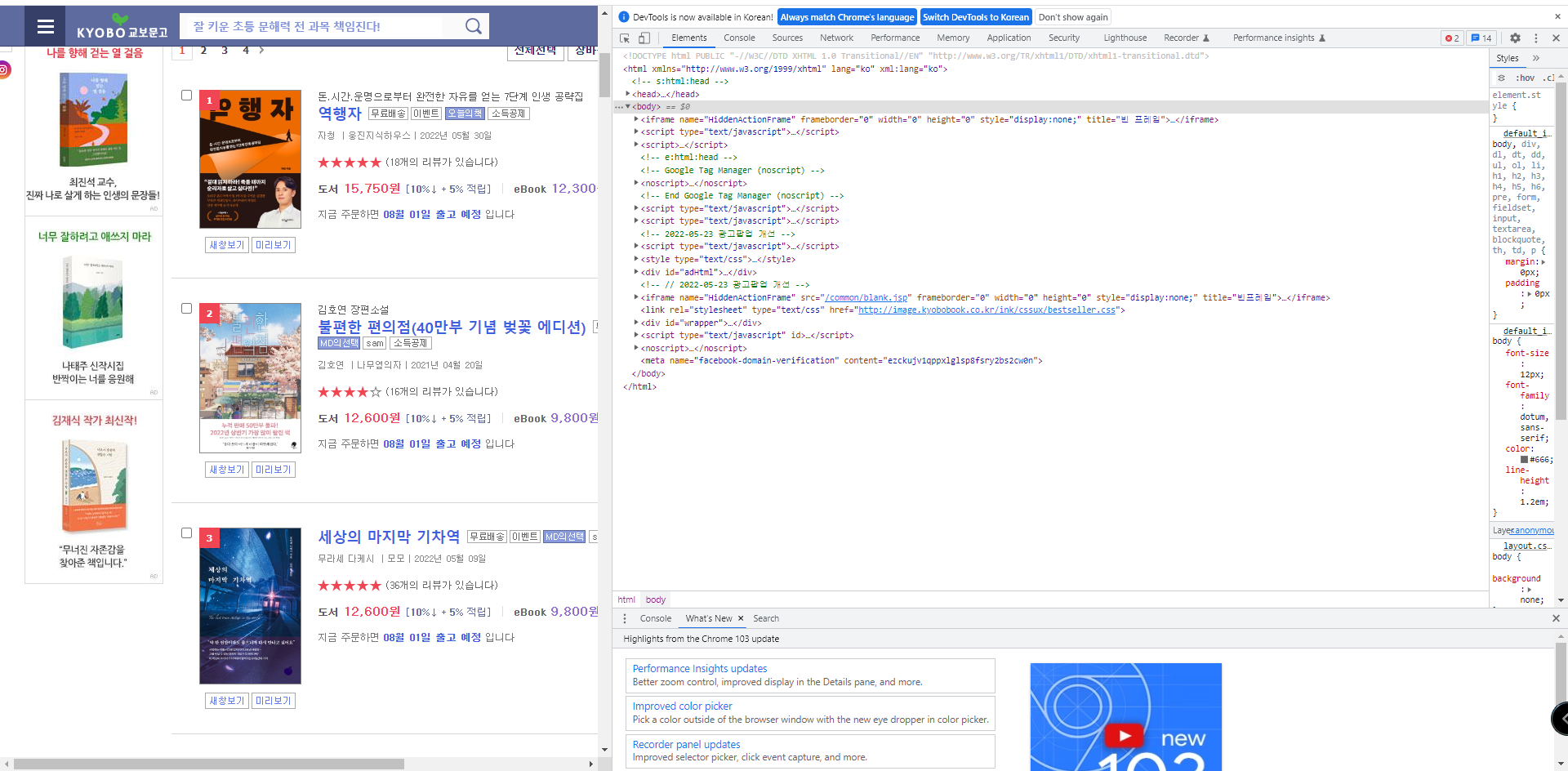
오른쪽 분할화면 왼쪽 상단의 화살표를 누릅니다.
제목을 클릭하면 이렇게 보입니다.
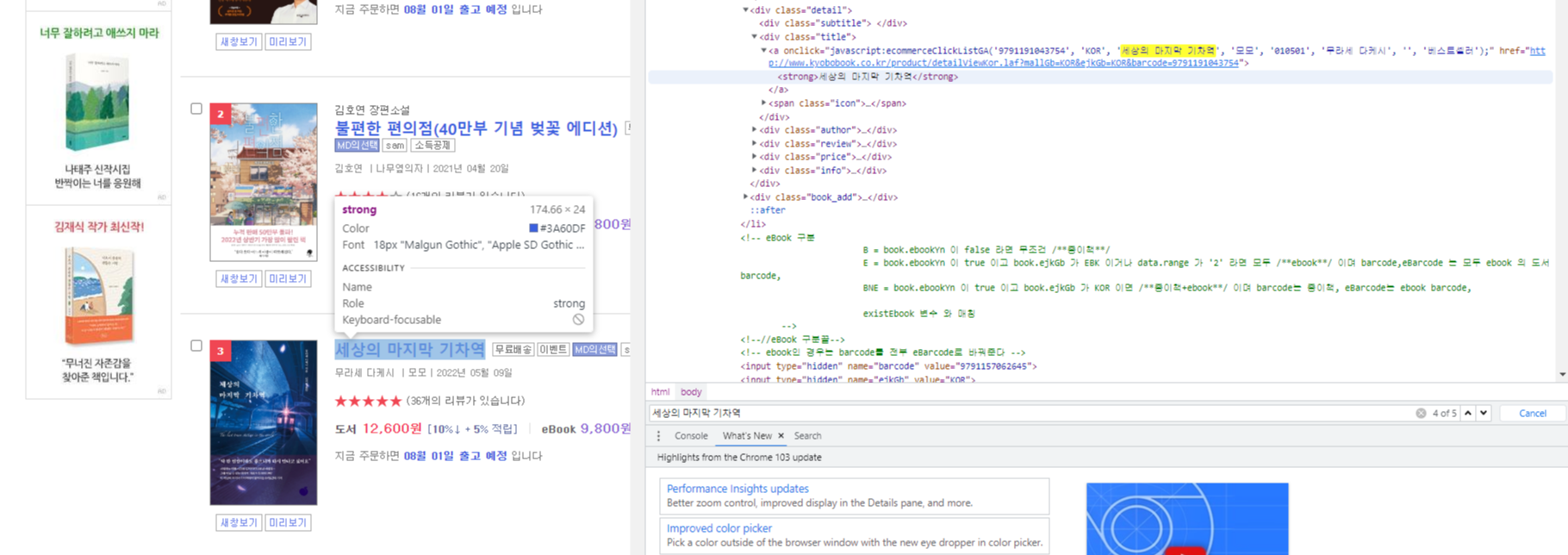
class ="title"이라고 보이죠?
아까 코딩에 그대로 넣어보겠습니다. 사이트 주소, select 뒤에 title을요.
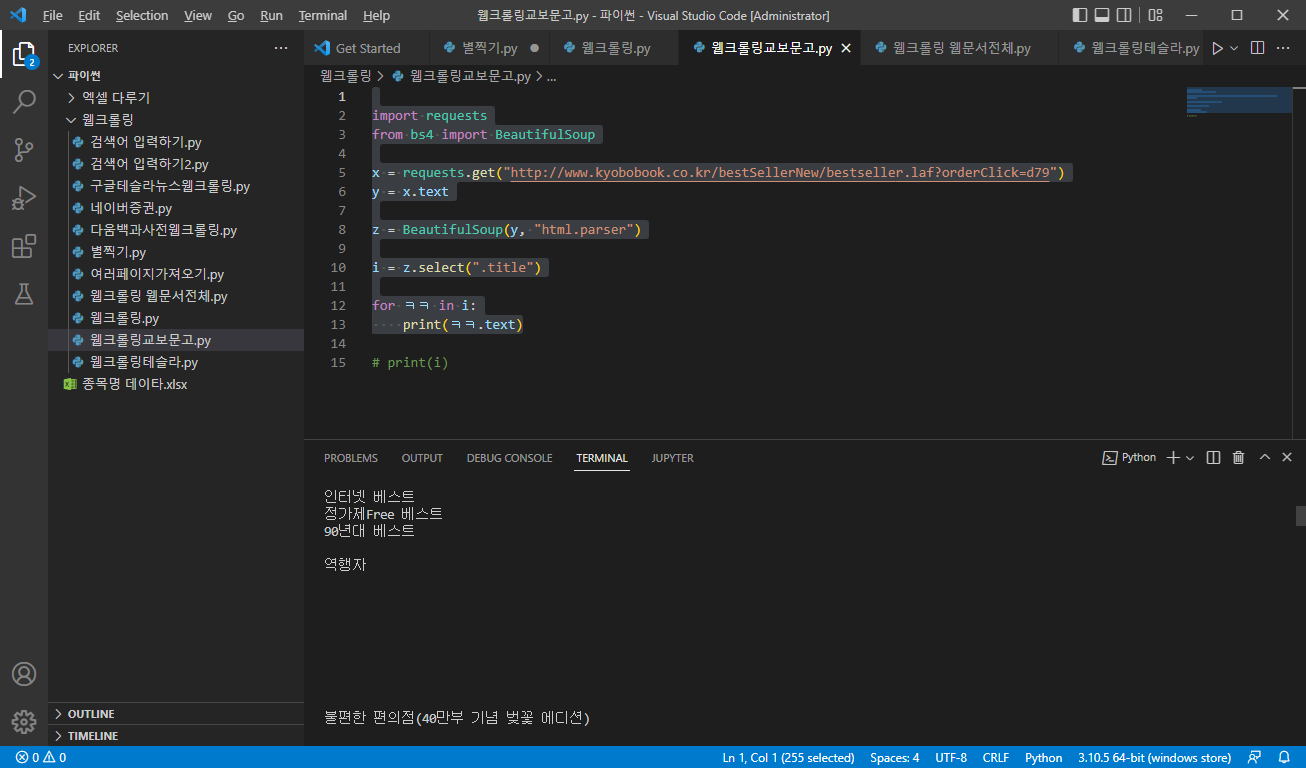
된 것 같은데, 다른 타이틀도 다 보인다는게 문제입니다.

보니까 파란색 볼드체로 되어 있는
종합베스트
정가제Free 베스트
90년대 베스트
이런 것들이 같이 출력되었네요. 그래도 결과값이 꽤나 우리가 원했던 것들입니다.
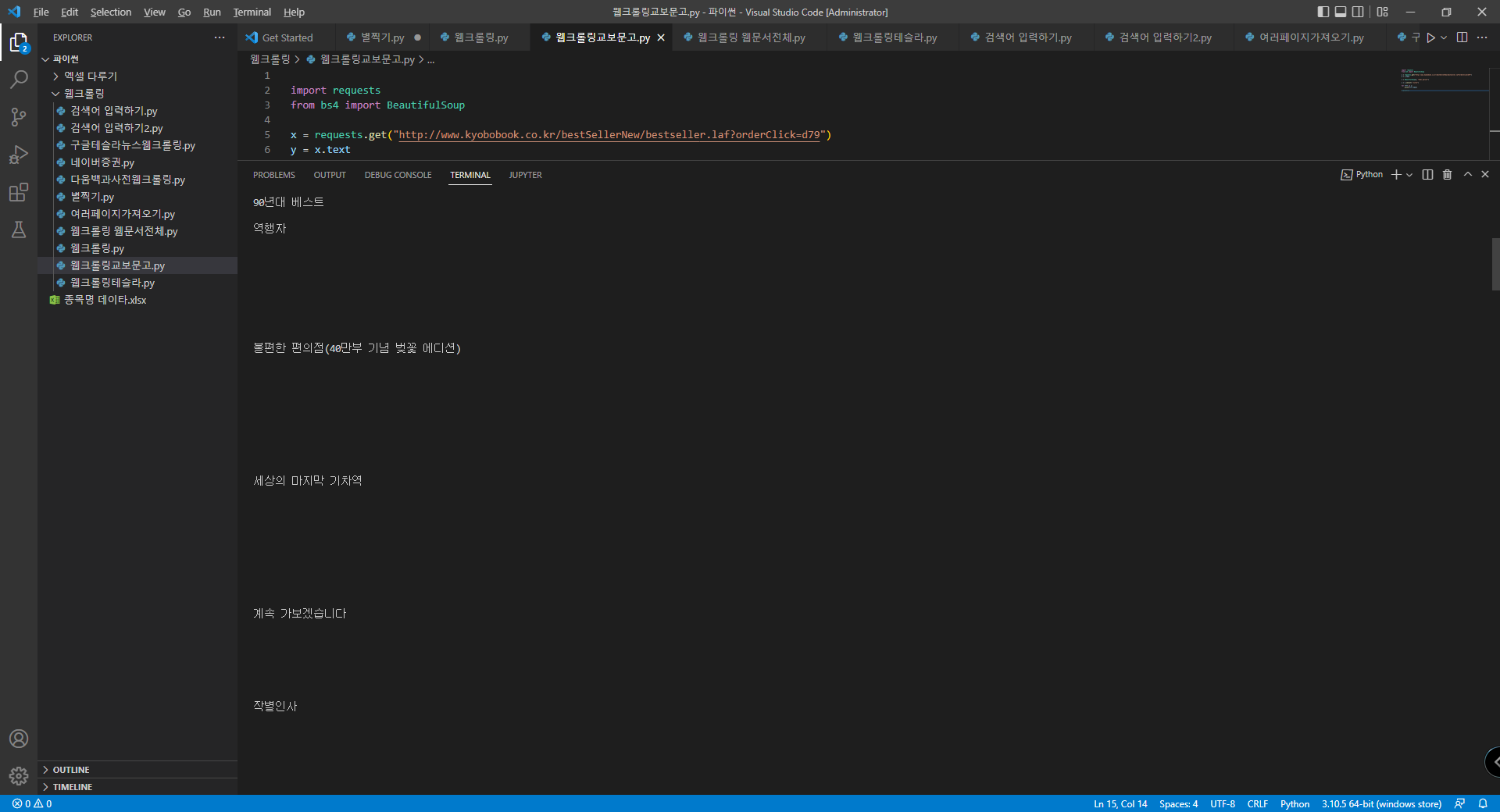
베스트들이 그대로 보이죠?
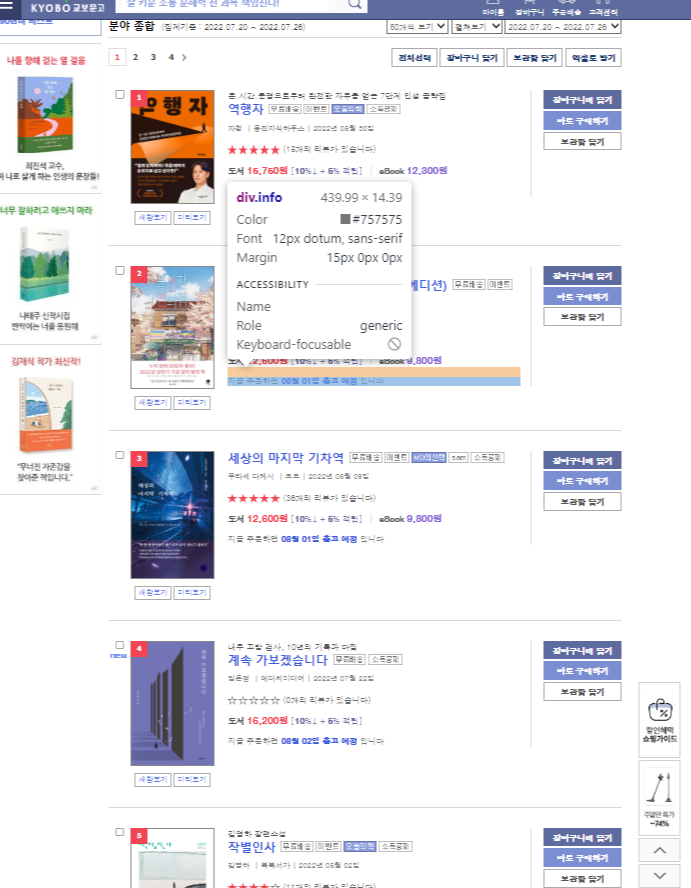
이 정도면 뭐... (웃음)
그러면 다음주는 매일 변동되는 환율을 한번 자동으로 끌고와 볼까요?
'파이썬 배우기' 카테고리의 다른 글
| 파이썬으로 웹크롤링한 정보를 엑셀로 저장하기 #2편 (0) | 2022.08.07 |
|---|---|
| 파이썬으로 웹크롤링한 정보를 엑셀로 저장하기 #1편 (0) | 2022.08.04 |
| 파이썬으로 웹크롤링 해 보기!!! 번외편 #2편 (진도 나가기 전 복습하기!!!) (0) | 2022.07.26 |
| 파이썬으로 웹크롤링 해 보기!!! 번외편 (진도 나가기 전 복습하기!!!) (0) | 2022.07.19 |
| 파이썬으로 웹크롤링 해 보기!!! 6편 (ft. 검색어 변경하기 - 이어서) (0) | 2022.07.05 |




댓글