728x90
반응형
저번 시간에 이어 웹크롤링 정보를 엑셀로 저장해 보도록 하겠습니다.
파이썬으로 웹크롤링한 정보를 엑셀로 저장하기 #1편
저번 시간까지는 웹크롤링하여 웹페이지에서 헤드라인 정보, 책제목 등을 가져와 봤습니다. 2022.07.31 - [파이썬 배우기] - 파이썬으로 웹크롤링 해 보기!!! 번외편 #3편 (교보문고 베스트셀러 웹크
booknomad.tistory.com
저번 시간에 교보문고 사이트에서 베스트 셀러 순위와 책 제목을 가져왔죠?
import requests
from bs4 import BeautifulSoup
y = x.text
z = BeautifulSoup(y, "html.parser")
i = z.select(".rank, .title")
for ㅋㅋ in i:
print(ㅋㅋ.text)
자, 합치기 전에 먼저 엑셀 만드는 방법에 대해서 먼저 배워보겠습니다.
import openpyxl
wb = openpyxl.Workbook()
ws = wb.create_sheet('교보문고 책제목')
ws.append(['순위', '책제목'])
wb.save('교보문고 베스트셀러.xlsx')
이렇게 하면 이렇게 생성이 됩니다.
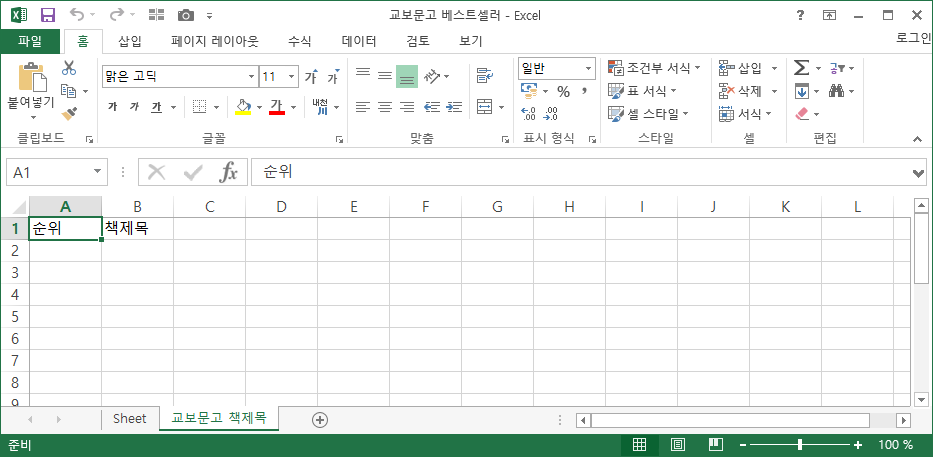
자, 이제 이 둘을 합쳐볼까요?
import requests
from bs4 import BeautifulSoup
import openpyxl
wb = openpyxl.Workbook()
# wb = Workbook(write_only = True)
ws = wb.create_sheet ('교보문고 책제목')
ws.append(['순위', '책제목'])
y = x.text
z = BeautifulSoup(y, "html.parser")
i = z.select(".rank, .title")
# j = i.text
for ㅋㅋ in i:
row = [i[0].get_text(), i[1].get_text()]
# print(row)
ws.append(row)
# print(i)
wb.save('교보문고 22년 베셀 순위.xlsx')
결과는요?
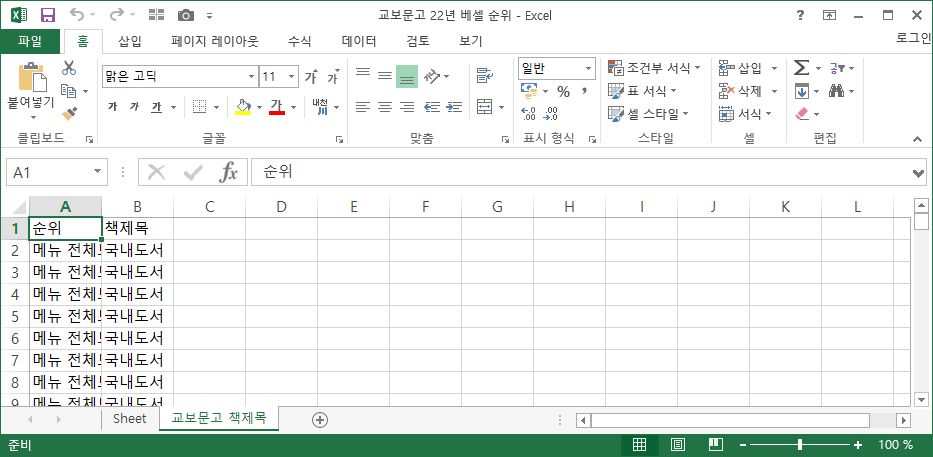
뭔가 가져왔는데, 어딘가 코딩이 잘못된 구석이 있나 봅니다. 다음 시간에 코딩을 더 들여다 보겠습니다.
그러니까 절차적으로는 이렇게 작업하면 됩니다.
1. 웹크롤링으로 웹페이지의 특정정보를 가져온다.
2. 그것도 텍스트만 가져온다
3. 그걸 엑셀에 저장한다.
728x90
반응형
'파이썬 배우기' 카테고리의 다른 글
| 파이썬으로 웹크롤링한 정보를 엑셀로 저장하기 #1편 (0) | 2022.08.04 |
|---|---|
| 파이썬으로 웹크롤링 해 보기!!! 번외편 #3편 (교보문고 베스트셀러 웹크롤링!!!) (0) | 2022.07.31 |
| 파이썬으로 웹크롤링 해 보기!!! 번외편 #2편 (진도 나가기 전 복습하기!!!) (0) | 2022.07.26 |
| 파이썬으로 웹크롤링 해 보기!!! 번외편 (진도 나가기 전 복습하기!!!) (0) | 2022.07.19 |
| 파이썬으로 웹크롤링 해 보기!!! 6편 (ft. 검색어 변경하기 - 이어서) (0) | 2022.07.05 |




댓글