저번 시간까지는 웹크롤링하여 웹페이지에서 헤드라인 정보, 책제목 등을 가져와 봤습니다.
2022.07.31 - [파이썬 배우기] - 파이썬으로 웹크롤링 해 보기!!! 번외편 #3편 (교보문고 베스트셀러 웹크롤링!!!)
파이썬으로 웹크롤링 해 보기!!! 번외편 #3편 (교보문고 베스트셀러 웹크롤링!!!)
자, 저번 시간에 여기까지 나갔습니다. import requests from bs4 import BeautifulSoup x = requests.get("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%ED%85%8C%EC%8A%AC%EB%9D%..
booknomad.tistory.com
그렇다면 그렇게 가져온 정보를 엑셀로까지 가져오는 방법을 배워보겠습니다. 그렇지 않고서야 파이썬 터미널에 나온 데이터를 드래그 복사해서 다시 엑셀에 붙이는 번거로운 작업을 해야 합니다.
일단 환율 정보를 가져오는 코딩 해 보겠습니다. 책 제목 가져올 때 쓴 기본 구문 그대로 가져와 보겠습니다.
여기서 사이트를 바꿉니다.
여기 사이트입니다.
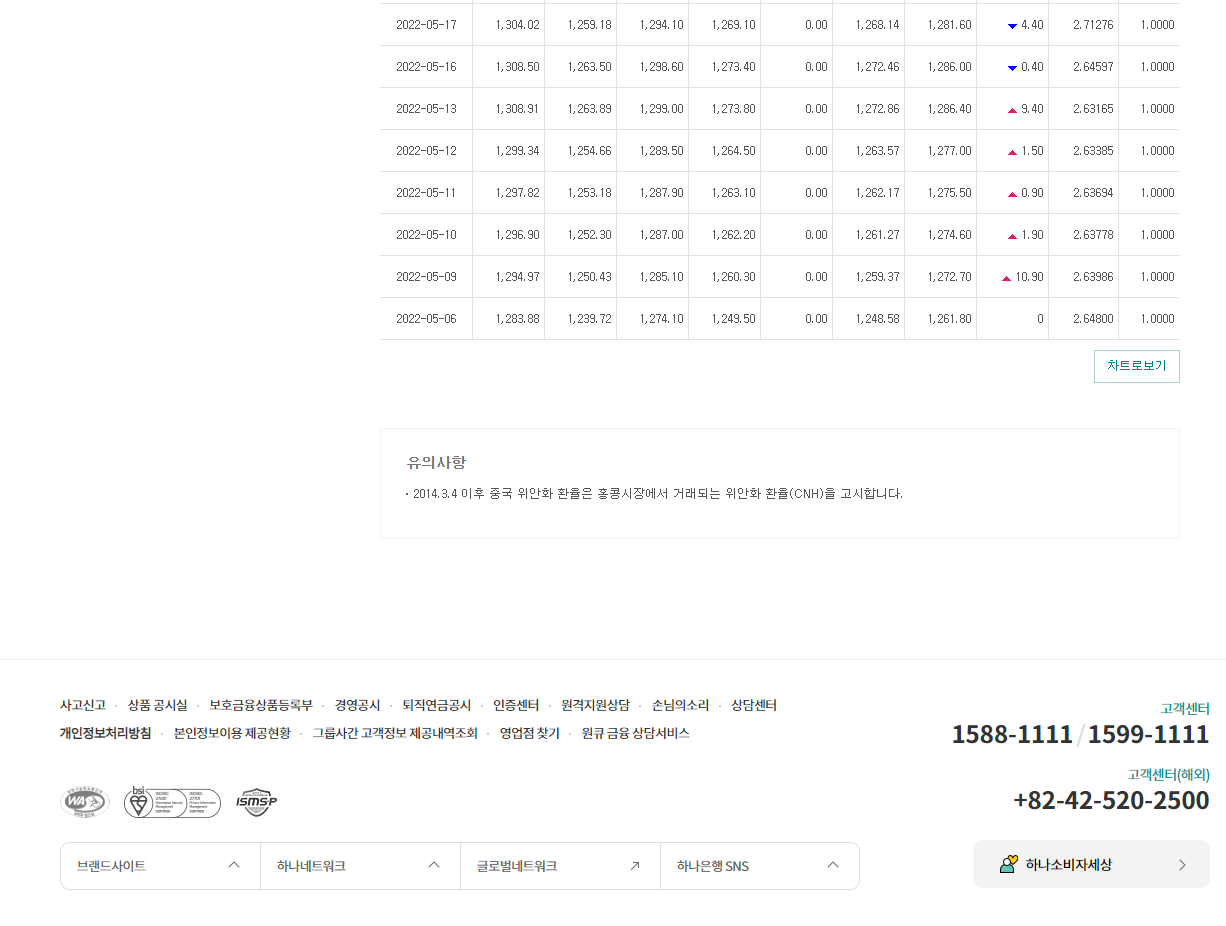
https://www.kebhana.com/cont/mall/mall15/mall1501/index.jsp
현재환율 < 환율/외화예금 금리 < 상품 < 하나은행
Home>외환>환율/외화예금 금리 locate --> 환율/외화예금 금리 --> --> 현재환율 --> -->
www.kebhana.com

브랜드사이트의 class가 title입니다.
그럼 그걸 바꿔볼까요?
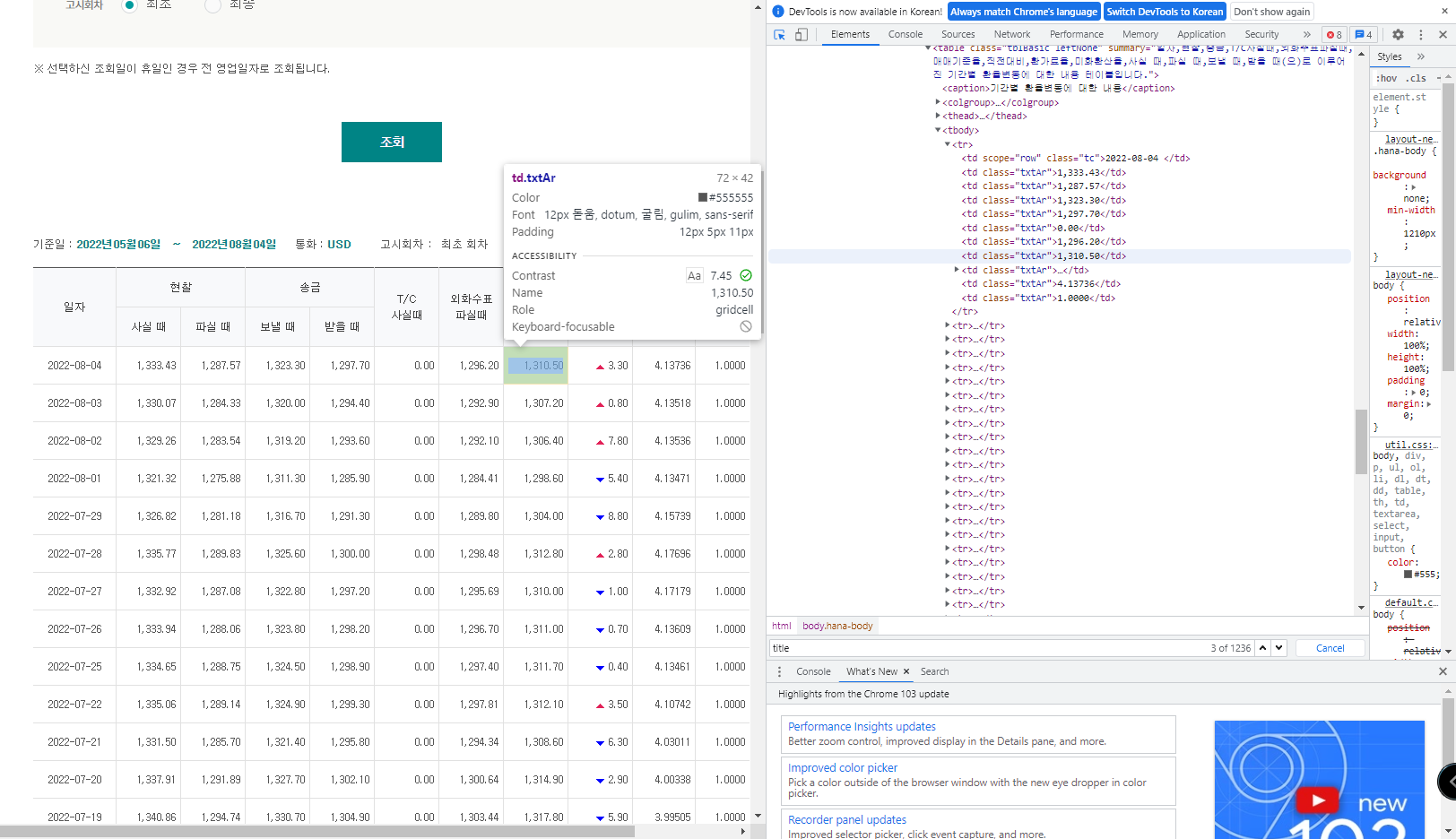
결과값이 나오지 않습니다. 더 공부를 해서 업데이트를 해 보고, 그럼 다른 사이트에서 해 보겠습니다.

[인베스팅닷컴에서 환율정보 가져오기]
https://kr.investing.com/currencies/usd-krw
USD KRW | 미달러 원 환율 - Investing.com
USD/KRW 미달러 원 환율 실시간 스트리밍 차트, 변환기와 기술 분석
kr.investing.com

자, 그럼 더 자세히 알면 더 해보고요. 일단은 기존에 성공한 책제목을 엑셀로 가져오는 방법을 공부해보겠습니다.
먼저 엑셀파일을 조작할 수 있는 라이브러리를 설치해 줘야 합니다.
터미널에서
pip install openpyxl
을 적고 엔터를 칩니다. 전 이미 설치가 되었다고 뜨네요.

먼저 교보문고 책제목을 가져온 코딩 가져와보겠습니다.
사이트는 여기였습니다.
http://www.kyobobook.co.kr/bestSellerNew/bestseller.laf?orderClick=d79
교보문고 종합 주간 집계 | 국내도서 | 베스트셀러 - 교보문고
www.kyobobook.co.kr
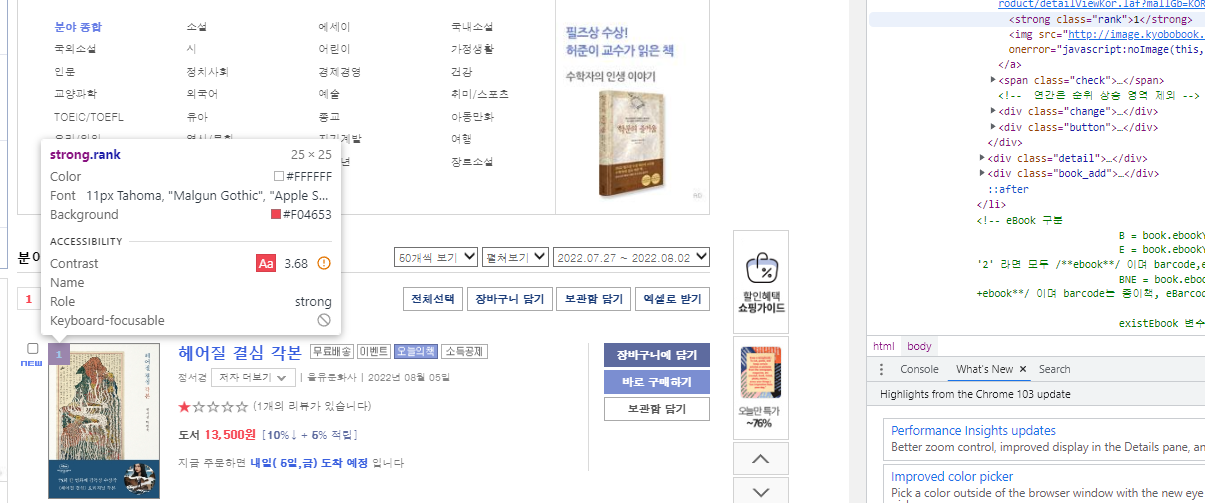
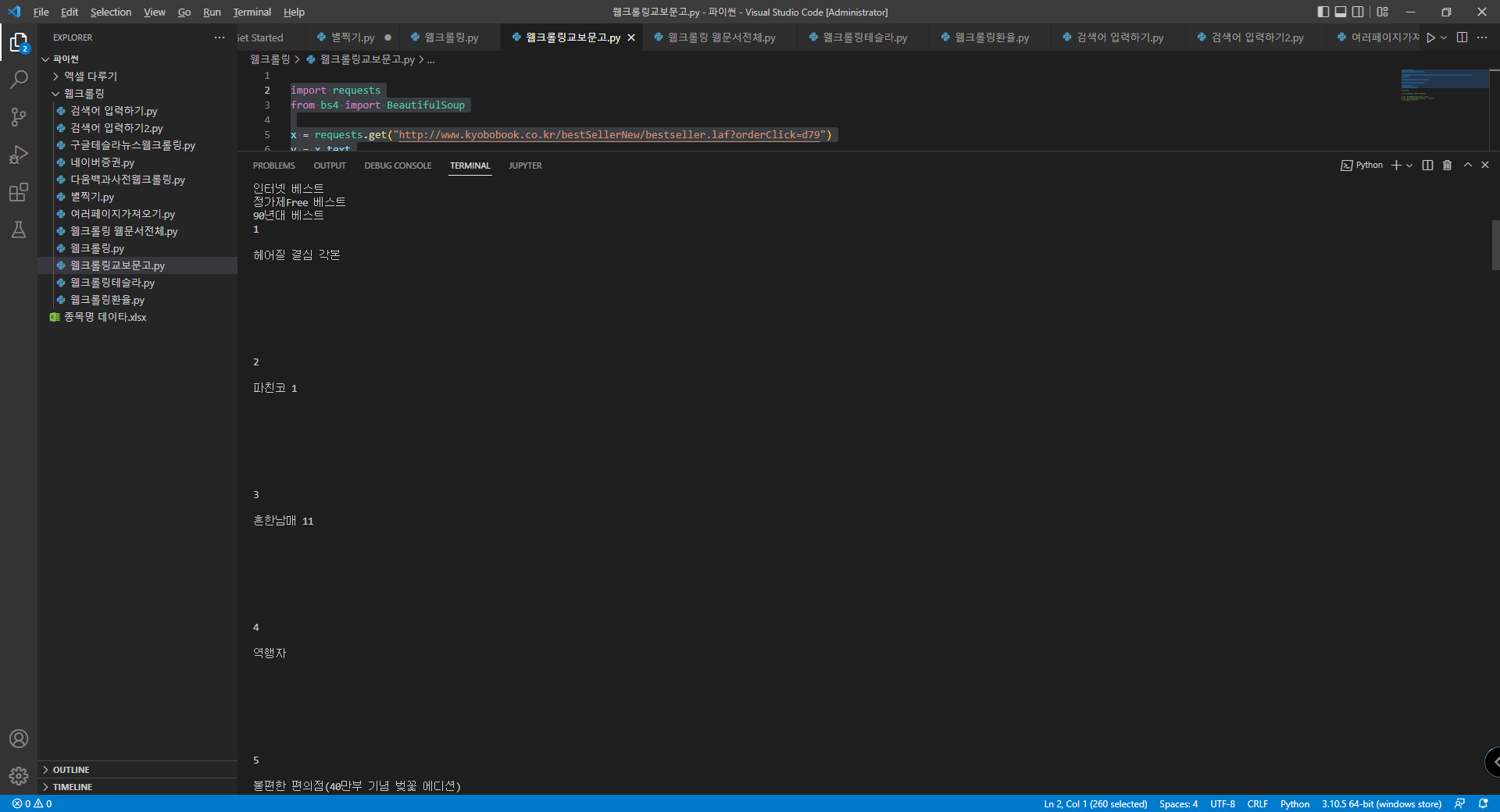
대박이죠?
다음 시간에는 이걸 엑셀로 출력하기 해 보겠습니다. 기대하세요^^
'파이썬 배우기' 카테고리의 다른 글
| 파이썬으로 웹크롤링한 정보를 엑셀로 저장하기 #2편 (0) | 2022.08.07 |
|---|---|
| 파이썬으로 웹크롤링 해 보기!!! 번외편 #3편 (교보문고 베스트셀러 웹크롤링!!!) (0) | 2022.07.31 |
| 파이썬으로 웹크롤링 해 보기!!! 번외편 #2편 (진도 나가기 전 복습하기!!!) (0) | 2022.07.26 |
| 파이썬으로 웹크롤링 해 보기!!! 번외편 (진도 나가기 전 복습하기!!!) (0) | 2022.07.19 |
| 파이썬으로 웹크롤링 해 보기!!! 6편 (ft. 검색어 변경하기 - 이어서) (0) | 2022.07.05 |




댓글